
作为人类,我们面临的挑战是发现所有模式。当然,我们有直觉来限制自己的猜测。但计算机没有这样的直觉。从计算机的角度来看,模式识别中的难题是只采用一个模式:在多种模式实际上都可行的情况下,什么决定了哪个模式是正确的?其它模式都是错误的?
数月之前,我阿姨给其同事发送了一封主题为「数学难题!答案是什么?」的邮件,邮件包含了一个谜题:
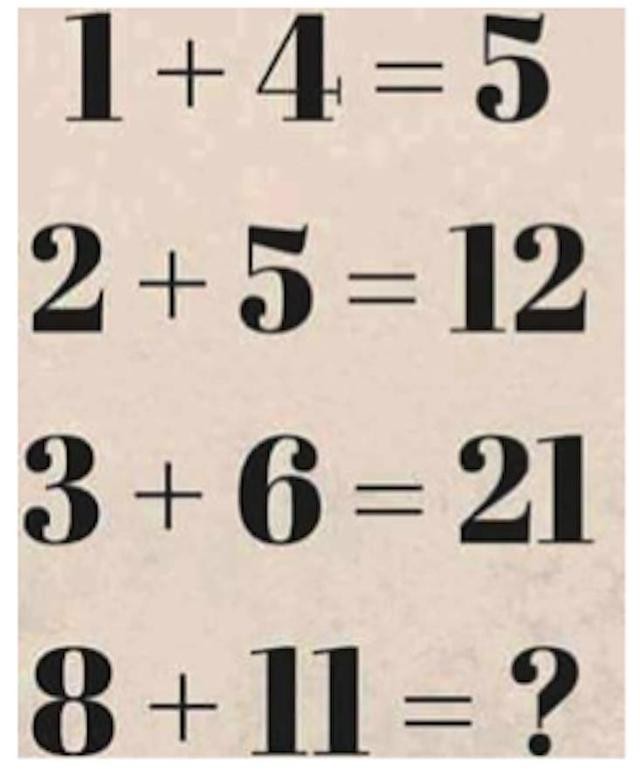
她认为自己的答案明显是正确的,她的同事们却认为他们自己的答案才是对的但这两个答案却不一样。那是他们的答案有一个是错的呢?还是谜题本身有问题?
我阿姨和她的同事偶然间发现了机器学习中的一个基本问题。我们期望计算机做的所有学习以及我们人类自身的学习都是将信息归纳成基本的模式,然后再用其来推断未知。她的谜题也毫不例外。
作为人类,我们面临的挑战是发现所有模式。当然,我们有直觉来限制自己的猜测。但计算机没有这样的直觉。从计算机的角度来看,模式识别中的难题是只采用一个模式:在多种模式实际上都可行的情况下,什么决定了哪个模式是「正确」的?其它模式都是「错误」的?
这个问题在近期才成为人们实际考虑的问题。20世纪90年代之前,人工智能系统几乎不做太多学习。例如,DeepBlue的前身国际象棋系统DeepThought,通过从成功与失败对赛中学习却并没能很好掌握国际象棋。相反,国际象棋大师和编程人员谨慎的书写规则,教计算机哪个落子位置是好还是坏。这样庞大的人工工作是「专家系统」时代的典型方法。
然后,人们就可以命令计算机遵循x*(y+1)=z模式。将该规则应用到最后一题,答案就是96。
尽管早期专家系统很成功,但需要人工设计、调整、更新系统,这会使得它们变得很笨重。相反,研究人员将注意力转移到了设计能自己推断模式的机器上。也就是一个程序能够检查数千张图片或市场交易数据,并提取出表明一张脸或一个紧急价格峰值的统计信号。这种方法很快成为了主流,也从此增强了从自动邮件分拣到垃圾邮件过滤和信用卡诈骗检测等各种任务。
如今,虽有有着如此多的成功,但这些机器学习系统仍需要工程师。再次回到上面的谜题,我们假设每个等式有3个相关组件(等式中的3个数值)。但也存在潜在的第四个元素:前面一个等式的结果。一个等式的属性,用机器学习的说法也就是特征,也考虑在内,那就生成了一个另外一种合理的模式:
所以,哪种模式是正确的?两个都正确,当然或者两个都不正确。这完全由允许使用哪种模式所决定。你甚至还可以这么做:第一个数乘以第二个数,然后加上上一行答案加上3后的五分之一,然后取离结果最近的整数。(这很诡异,但却有效)而且,如果我们允许包含数值视觉形式的特征,我们可能还能得到一些关于字形和字体的模式。该模式匹配取决于观察者的假设。

发表评论